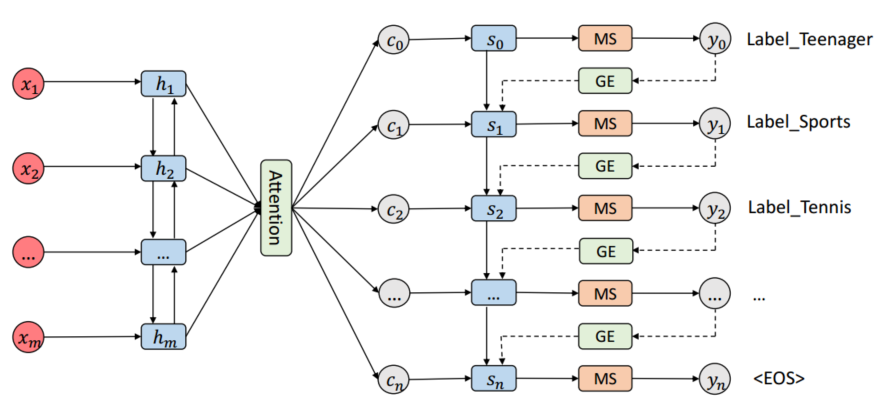
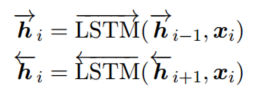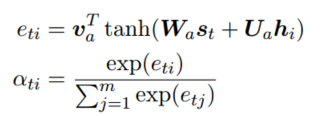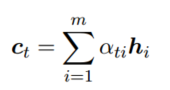任务
- 重新训练一个小网络
- 使用预训练模型得到的特征
微调预训练模型
fit_generator训练
- ImageDataGenerator做实时的数据增强
- layer freezing 和 模型 fine-tuning
目录设置和数据集划分
1 | """ |
数据预处理和数据增强
keras.preprocessing.image.ImageDataGenerator class
- 训练的时候可以标准化
1 | keras.preprocessing.image.ImageDataGenerator(featurewise_center=False, |
- featurewise_center:布尔值,使输入数据集去中心化(均值为0), 按feature执行
- samplewise_center:布尔值,使输入数据的每个样本均值为0
- featurewise_std_normalization:布尔值,将输入除以数据集的标准差以完成标准化, 按feature执行
- samplewise_std_normalization:布尔值,将输入的每个样本除以其自身的标准差
- zca_whitening:布尔值,对输入数据施加ZCA白化
- zca_epsilon: ZCA使用的eposilon,默认1e-6
- rotation_range:整数,数据提升时图片随机转动的角度
- width_shift_range:浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度
- height_shift_range:浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度
- shear_range:浮点数,剪切强度(逆时针方向的剪切变换角度)
- zoom_range:浮点数或形如[lower,upper]的列表,随机缩放的幅度,若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range]
- channel_shift_range:浮点数,随机通道偏移的幅度
- fill_mode:;‘constant’,‘nearest’,‘reflect’或‘wrap’之一,当进行变换时超出边界的点将根据本参数给定的方法进行处理
- cval:浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充的值
- horizontal_flip:布尔值,进行随机水平翻转
- vertical_flip:布尔值,进行随机竖直翻转
- rescale: 重放缩因子,默认为None. 如果为None或0则不进行放缩,否则会将该数值乘到数据上(在应用其他变换之前)
- preprocessing_function: 将被应用于每个输入的函数。该函数将在图片缩放和数据提升之后运行。该函数接受一个参数,为一张图片(秩为3的numpy array),并且输出一个具有相同shape的numpy array
- data_format:字符串,“channel_first”或“channel_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channel_last”对应原本的“tf”,“channel_first”对应原本的“th”。以128x128的RGB图像为例,“channel_first”应将数据组织为(3,128,128),而“channel_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channel_last”
1 | from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img |
训练一个小的卷积神经网络
1 | from keras.preprocessing.image import ImageDataGenerator |
1 | train_data_dir = 'data/train' |
1 | import numpy as np |
1 | from keras import applications |