SGM: Sequence Generation Model for Multi-Label Classification论文学习
Abstract
- 1、先介绍背景 ;
多标签分类在nlp领域具有很大挑战性,而且标签之间往往有关系,这比单个标签分类难多了;- 2、介绍已有研究主要存在的问题 ;
2.1 现有方法经常忽略标签间的关系;
2.2 现有方法没有考虑文本的不同部分预测标签的贡献不一样;- 3、简要概括自己提出的方法 ;
将多标签任务视为序列生成问题,应用序列生成模型,一种比较创新的解码器结构来解决。- 4、说明实验结果并简要分析 ;
大量实验结果表明,提出的方法在很大程度上优于以前的工作。 对实验结果的进一步分析表明,所提出的方法不仅捕获标签之间的相关性,而且在预测不同标签时自动选择信息量最大的单词。
1 Introduction
1、具体解释多标签分类问题是什么;
2、介绍之前传统机器学习的劣势:
(1)Binary relevence (BR) : 忽略了标签的相关性;
(2)Classifier chains(CC): 考虑标签的相关性,将多标签转化为链式二分类,计算量太大;
(3)ML-KNN:捕捉一阶或两阶标签相关性,在高阶标签相关性计算复杂度过高;
3、神经网络方法:
(1)they either neglect the correlations between labels or do not consider differences in the contributions of textual content when predicting labels
4、大概讲讲怎么启发想到这个方法,简要描述这个方法,并说明这个方法解决什么问题有什么效果。最后列举贡献点
(1)提出的解码器采用序列生成模型,能够捕捉标签间的相关性还有自动获取最有用的信息来预测不同的标签;
(2)大量实验表明这个方法优于其他方法,进一步的分析说明了所提出方法能有效表示标签间的相关性
5、说明论文结构
2 Proposed Method
2.1 Overview
y*是要预测的序列标签,要最大化条件概率p(y|x):
$$ p(y|x) = \prod_{i=0}^n p(y_i|y_1,y_2,..,y_{i-1}) $$
将训练集中按照标签的频率排序,频率搞得排前面。
模型框架
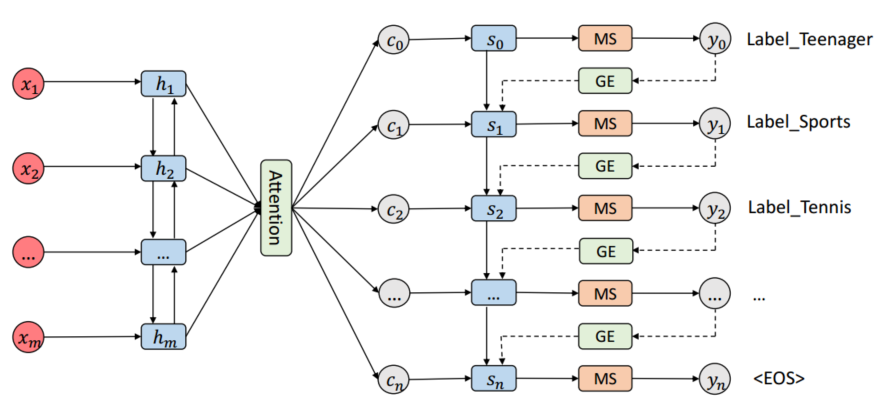
MS denotes the masked softmax layer. GE denotes the global embedding
The text sequence x is encoded to the the hidden states, which are aggregated to a context vectorct by the attention mechanism at time-step t. The decoder takes the context vector ct, the last hidden state st−1 of the decoder and the embedding vector g(yt−1) as the inputs to produce the hidden state st at time-step t. Here yt−1 is the predicted probability distribution over the label space L at time-step t − 1. The function g takes yt−1 as input and produces the embedding vector which is then passed to the decoder. Finally, the masked softmax layer is used to output the probability distribution yt.
2.2 Sequence Generation
Encoder:
$ (w_1,w_2,..,w_m) $是有$ m $个词的一句话,用one-hot表示,$w_i$经过word-embedding变成$x_i$,然后用双向的LSTM读取$x$,计算每个单词的隐藏层的状态,如下:
Attention:
Decoder:
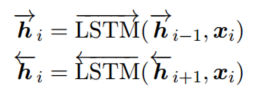
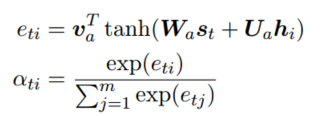
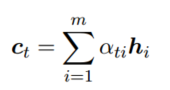
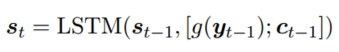
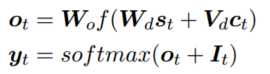

2.3 Global Embedding
3 Experiments
3.1 Dataset
公开数据集合私有数据集做的实验,这样更有说服力
3.2 Evaluation Metrics
Hamming-loss和Micro-F1
3.3 Details
网络参数的介绍
adam
3.4 Baseline
介绍列举以前的方法作为baseline
3.5 Results
3.6 Analysis and Discussion
global embedding加进去效果提升很多;
mask用来阻止预测重复的标签;
标签的排序也很有效;
可视化attention;

